Recycling Is Good! – Sharing Knowledge from One Individual to Another in a Multiple-Cue Judgment Task
Nordvall A C
Umea School of Business and Economics, Umea University, Umea School of Business and Economics, Biblioteksgrand 6, 901 87 Umea, Sweden.
*Corresponding Author
Anna-Carin Nordvall,
Umea School of Business and Economics,
Umea University, Umea School of Business and Economics,
Biblioteksgrand 6, 901 87 Umea,Sweden.
E-mail: anna-carin.nordvall@usbe.umu.se
Received: June 05, 2014; Accepted: June 24, 2014; Published: June 25, 2014
Citation: Nordvall A C (2014) Recycling Is Good! – Sharing Knowledge from One Individual to Another in a Multiple-Cue Judgment Task. Int J Behav Res Psychol. 2(5), 47-52. doi: dx.doi.org/10.19070/2332-3000-140009
Copyright: Nordvall A C© 2014. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.
Abstract
The cognitive models exemplar memory and cue abstraction was examined in two experiments in a multiple-cue judgment task with verbalization to see how the models was affected by verbalization and how verbalization could improve individual learning. The results showed that verbalization increase individual learning and that the judgments in the analogue condition were significantly better than the proposition condition overall. Strong exemplar effects was shown for all groups regardless of stimulus presentation and learning mode, even for the learning individuals conditions that learned from written verbalized information in the absence of outcome feedback. The results suggest that exemplar memory works as a backup system similar to previous research and that exemplar-based knowledge could be the regular result of cooperation, even without social interaction.
2.Introduction
3.Material
3.1.Judgment task and prediction
4.Method
4.1.Participants
4.2.Design and Procedure
4.3.Training phase
4.4.Test phase
5.Results
5.1.Performance
5.2.Learning
5.3.Presentation format
5.4.Model fit
6.Discussion
7.References
Keywords
Multiple-Cue Judgment; Cognitive Processes; Cooperation; Verbalization; Learning.
Introduction
Multiple cue judgments tend to be well captured by multiple linear regression models (Cooksey, 1996; Hammond & Stewart, 2001), often interpreted as cue abstraction or exemplar memory (Juslin, Olsson & Olsson, 2003). The exemplars are holistic concrete experienced instances (Medin & Schaffer, 1978; Nosofsky & Johansen, 2000). At the time of judgment, the constraint to iterative adjustment implies an additive integration of the linear and independent effects of the cues on the criterion and, this in turn, entails that cue abstraction can only represent tasks where the cues relate to the criterion by a linear additive function (Olsson, Enqvist & Juslin, 2006). The additive combination of the criteria of exemplars with exemplar memory can represent any task structure as long as similar exemplars have similar criteria, allowing accurate judgment also in nonlinear tasks. This advantage of exemplar models has long been recognized in the related field of categorization learning (see, e.g., Estes, 1994; Medin & Schaffer, 1978; Smith & Minda, 2000).
Previous research suggest that exemplar memory acts as a general back-up systems and is part of a flexible interplay between multiple levels of knowledge representation, as feedback (or task itself) will not allow a deeper structure induced (Juslin et al., 2003; Olsson, et al., 2006). This more profound structural released for rule-based representations as fast feedback allows. These results mean that the present experiments can be expected to result in a rule-based knowledge representation for both verbalizing and learning individual conditions because the interaction receives a comprehensive, verbalized and abundant feedback. According to Nosofsky (1989), we can use exemplar-based representations even when the exemplars have been presented as explicit linguistic rules. In contrast, Juslin et al. (2003) argues that explicit rules (verbalized or not) leads the person to use cue-abstraction.
The aim is to investigate whether there is any difference in learning speed, performance and knowledge representation depending on whether the learning is made by written verbalization or reading verbalized rules, and if the stimuli presentation analogue or propositional interact or form a single effect on learning. The intention is also to investigate whether any of these factors alone or together affect knowledge representation in the direction of being a rule-based or exemplar-based.
Material
In the experiments below the participants use four binary cues to infer a continuous criterion in a multiple-cue judgment task (Juslin et al., 2003, Juslin et al., 2003). The cover story in the task involves judgments of the toxicity of subspecies of a fictitious bug, called the Hummer bug which can be inferred from four cues of the subspecies (leg length, nose length, spots or no spots on the fore back and different patterns on the buttock). The concentration of poison varies from 50 to 60 ppm in each subspecies. The binary cues take on values 1 or 0, where 1 suggests high toxicity and 0, low toxicity. The task is summarized in Table 1. In the linear task, the function relating the cues to the toxicity of a subspecies is linear and additive where the toxicity of the bug is specified by the present cues of the bug that hold different poison weights. The criterion is thus computed by assigning the most important cue, C1 the weight 4 (relative weight .4), while the least important cue C4 has weight 1 (relative weight .1).
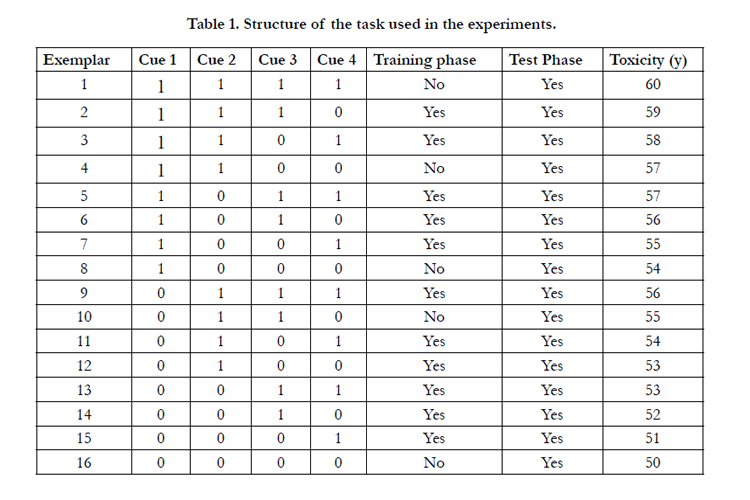

Table 1. Structure of the task used in the experiments.
Discrimination between the exemplar memory and cue abstraction involves extrapolation and interpolation, in other words, the ability to make accurate judgments for new exemplars. When participants are trained with the whole stimuli set (all 16 exemplars) it is impossible to discriminate between the models, because they predict the same judgments. When subspecies are withheld in the training phase (two extreme exemplars, e.g., [1 1 1 1] and [0 0 0 0] and three middle exemplars, [1 0 1 1], [10 1 0], [1 0 0 1], see Table 1 for new N, and old, O exemplars) and the participants are presented with the complete set of subspecies in the test phase, in a linear task the cue abstraction model affords accurate extrapolation and interpolation.
When relying on cue abstraction participants will thus consider that the extreme subspecies, with all cues for toxicity present or absent, should have the most extreme criterion values, even if they have never seen these subspecies in the training phase. This means that no systematic differences related to whether an exemplar is old or new are expected if the participants have abstracted the underlying cue criterion relations. By contrast, because the exemplar model involves linear combination of the criteria observed in training that range between 51 and 59, it can never produce a judgment outside of this range, as extrapolation requires (DeLosh, Busemeyer, & McDaniel, 1997; Erickson & Kruschke, 1998). The exemplar model predicts more accurate and correct judgments for old than new exemplars, because the judgment is based from retrieval of identical exemplars with the correct criterion (Juslin et al., 2003).
Note: Exp. = Extrapolation, Interp. = Interpolation, p=.5 assigns binary cue value 1 to the exemplar with probability .5. Exemplar 1 and 16 = Extrapolation exemplars and Exemplar 4, 8 and 10 =Interpolation exemplars.
Exemplar effects are not affected by analogue or Propositional encoding (Juslin et al., 2003). This suggests that the results of the present study should show exemplar effects independent of presentation form. Since there are few cognitive studies done on the importance of presentation form, the outcome is still uncertain, especially given that the specific judgment with no feedback for the receiving information individual group, this experiment is the first in its kind.
Method
150 undergraduate students from a Swedish University participated in the experiment, seventy five males and seventy five females, recruited as 30 gender homogeneous pairs (Verbalized Individuals (VI) and learning individuals (LI)) and a control group of Non-Verbalized Individuals (NVI). The mean age was 23.25 years and every participants received 50 SEK (approximately 7$) plus a bonus of up to 50 SEK from joint performance in payment for their participation in the experiment. Best pair-performance shared a profit of 400 SEK (approximately 60$). The payments were designed to increase motivation to participate and collaboration. Both members of the pairs were recruited at the same time and with the requirement that they knew each other slightly earlier to increasing the desire for a joint performance.
The experiments were designed with two independent variables a) Non-Verbalized Individual, Verbalized Individual and Learning Individual (in forthcoming text NVI, VI and LI will be used) b) analogue or proposition mode. The one-hundred and fifty participants were 30 gender homogeneous pairs for each stimuli mode and thirty individuals for the non-verbalized control group, males and females were distributed evenly in terms of gender and presentation form (proposition or analogue). Individuals in each pair were divided into VI that had to formulate written instructions about the stimuli exemplars and pass it over to the other individual in the pair (LI) that received the written verbalized instructions of the stimuli exemplars. In the same way the groups VI - analogue, LI - analogue, and VI - Propositions, LI – Propositions was constructed, so each of these groups consisted of 15 pairs (30 individuals). A group of 30 individuals was made as a control group to make the comparison of verbalization and non-verbalization possible. The dependent variable to determine issues concerning overall performance was the difference between the correct and declared response in the learning phase and the dependent variable to determine knowledge representation (cue abstraction or exemplar memory) was the difference between the correct and specified responses for old and new items in the test phase.
The judgment task was presented on a computer screen where the participants had to judge the toxicity of the hummer bugs. Besides the computers that were used during learning and test phase an extra computer to manage the transfer of information between the pair members was used. Computer equipment was standard IBM compatible PCs of relatively late date. The descriptions that VI wrote was saved on the desktop and sent to the LI via an online chat room constructed for experiment. The text was then presented on a display screen on the side of the screen that presented the judgment task. This was done for each block in the learning phase but not during the test phase, which by all means was similar for all participants.
Written instructions informed the participants that there were different subspecies of a Hummer Bug and that the task was to estimate the toxicity (poison level) as a number between 50 and 60 of the subspecies. The individuals in each pair, was informed that they have to work together to get the prize bonus and that the bonus was based on the performance of the LI that did not receive any feedback. The experiments contained two phases, where the first phase was a training phase which provided a trial-by-trial outcome feedback about the continuous criterion (“This bug has toxicity 56.7 %”). The outcome feedback was only provided for the VIs, the LIs received no outcome feedback on their performance in the training phase. The individuals in the control group (NVI) accessed feedback in the training phase, but not in the test phase, and did not verbalize their knowledge into written instructions.
The subspecies varied in regard to four binary cues; leg length (short or long), nose length (short or long), spots or no spots on the fore back and two different patterns on the buttock. Different colors were used for the cue values to strengthen their salience. The abstract cues in Table 1 were the same for the individual within a pair (Verbalized individual and Learning Individual) but randomly assigned to new features between pairs and the same for the control group individuals (Non-Verbalized Individuals). The question on the computer screen was “What is the toxicity of this subspecies?”
In the training phase 11 training exemplars of the bug were presented. For all conditions five exemplars were omitted in the training phase and first presented in the test phase. The participants were trained and tested with either propositions or analogue stimuli (images of bugs) presented on the computer screen. During the training phase, the LI did not receive any feedback and the only guidance was the written instructions formulated by the VI, and revised after each block of 55 judgments (four versions were produced, provided that the VI always had a few additions to make). The VI only had access to his latest description and only when it was time for revision of the instructions. The LI interrupted his judgments to await each new version of the description that had been saved on the desktop and sent to the chat room by the VI. The LI could then view the new instruction version so that it became visible on the computer screen. For each new description, the LI could ask the VI questions to obtain more information than was shown in the instruction. In the test phase, the VI did not handed out any revised instructions. The LI did not receive any feedback and had no longer access to the instruction previously shown along with the stimuli presentation. Once the test phase was completed, the experimenter paid the fees and bonuses. Prize money for top pair was paid at a later date when the study was completed.
In the test phase, all 16 exemplars were presented, including the five omitted exemplars in the training phase. The test phase went over 32 trials, where the 16 exemplars were presented twice in a random order. The participants made same judgments as in the training phase but received no outcome feedback. The experiment took approximately 45 minutes to complete.
Results
An Univariate ANOVA with VI-LI condition and presentation format as independent variables and Absolute Deviations between responses and actual values as dependent variable in the learning phase showed no main effect in the VI-LI condition (F1,116=0.00, MSE= 0.00, p=.995) but a main effect for the VINon VI condition was shown (F1,56=0.95, MSE= 0.43, p=.032) but no interactions effect between VI-Non VI condition and presentation format (F1,56=0.85, MSE= 0.07, p=.076). Further, the results showed a main effect of presentation format for the presentation form condition (Proposition/analogue) (F1,144=4.28, MSE= 1.111, p= .046), but no significant interactions between VI-LI condition and presentation form (F1,116=0.06, MSE=0.02, p=.808) (see Table 2). The same pattern was shown for the test phase including condition and presentation form as independent variables and Absolute Deviations between responses and actual values as the dependent variable with a main effect on VI-Non VI condition (F1,56=1.22, MSE= 0.24, p=.05), but no main effects on the VI-LI condition (F1,116=0.08, MSE= 0.03, p=.779), a main effect on presentation format (F1,144=5.17, MSE= 1.86, p=.029), but no interaction effect between VI – Non VI condition (F1,56=0.66, MSE= 0.04, p=.089) or VI-LI condition and presentation format (F1,116=0.07, MSE= 0.02, p=.796) (see Table 3).
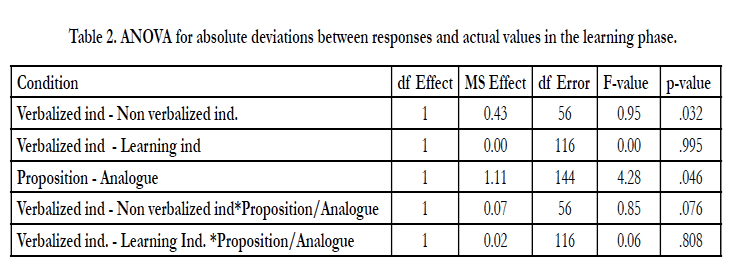
Table 2. ANOVA for absolute deviations between responses and actual values in the learning phase.
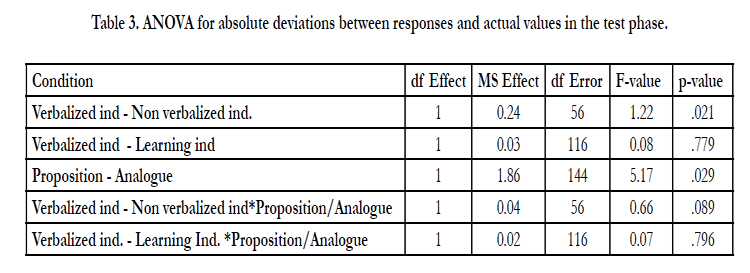
Table 3. ANOVA for absolute deviations between responses and actual values in the test phase.
According to Figure 1 the results show a faster learning curve for the LI in both presentation format conditions. Figure 1 shows the power function according to A=a+I*k<, where < is the numberof a specific judgment (1-220). A is the mean of the absolute deviation between response and the actual value for every single judgment, a is the intercept, which means the predicted value of Y when X continue to infinity. I determines the distance from 0 at the starting point of the curve. K indicates how fast the curve decrease from the initial position till it level away. This measure indicates the speed of learning.
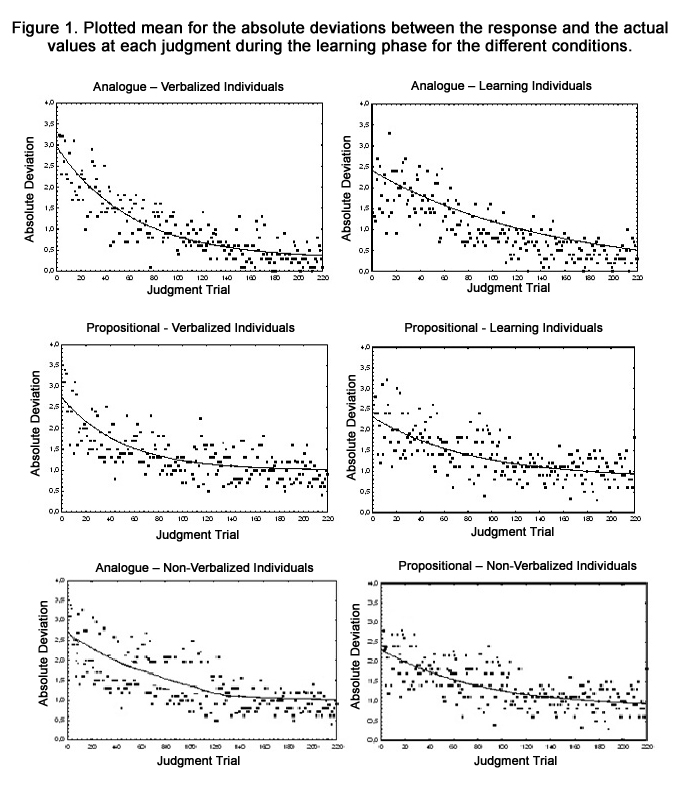
Figure 1. Plotted mean for the absolute deviations between the response and the actual values at each judgment during the learning phase for the different conditions.
An ANOVA with VI-LE condition and presentation format as independent variables and the difference between old and new exemplars as dependent variable in the learning phase shows no main effect in the VI-Non VI condition (F1,56=0.15, MSE=0.09, p=.755) or in the VI-LI condition (F1,116=0.13, MSE= 0.09, p=.718). Further, a main effect of presentation format was shown for the presentation form condition (Proposition/Analogue) (F1,144=0.10, MSE= 0.07, p= .751), and no significant interactions between VI-Non VI condition and presentation format form (F1,56=0.89, MSE=0.59, p=.411). The VI-LI condition showed the same pattern for interaction effects with presentation form (F1,116=0.91, MSE=0.59, p=.348) (see Table 4). This means that VI-LI is consistent in their judgments, which is expected when the LI has adopted the feedback given by the VI.
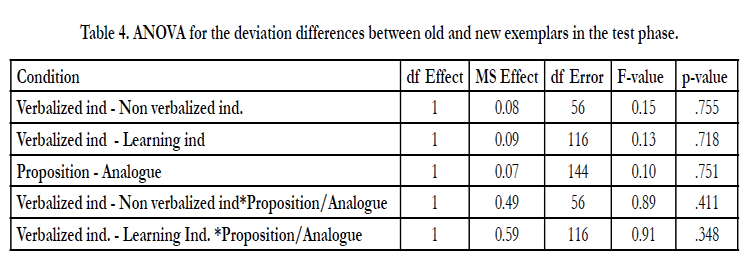
Table 4. ANOVA for the deviation differences between old and new exemplars in the test phase.
Mean values of the differences in the absolute deviation between the old and new exemplars and confidence intervals for each group are shown in Figure 2. Since the mean values are significantly different from 0 in all the groups, it is clear that the exemplar-based knowledge representation has been applied in all conditions. Some values in the propositional LI condition differs by slipping over on the plus side, which must be attributed to chance because this means better results in new than old exemplars. An important difference between presentation format shows that knowledge of the cues in the exemplar can be learned without direct experience (judgment feedback) of the specific cue
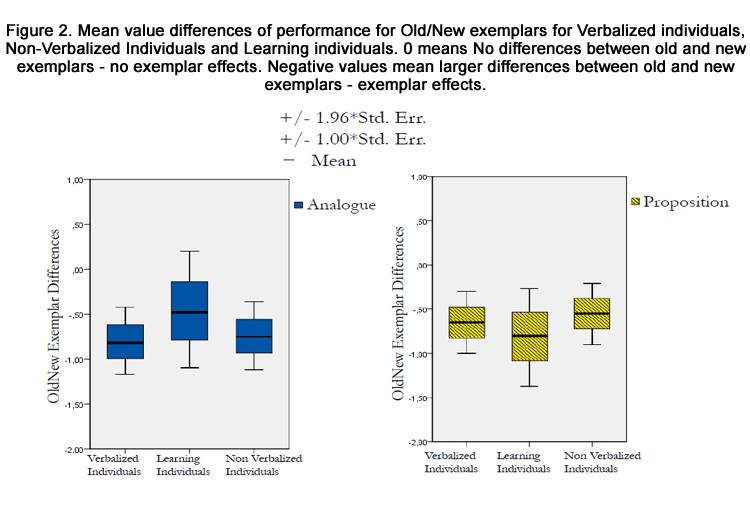
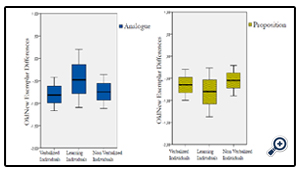
Figure 2. Mean value differences of performance for Old/New exemplars for Verbalized individuals, Non-Verbalized Individuals and Learning individuals. 0 means No differences between old and new exemplars - no exemplar effects. Negative values mean larger differences between old and new exemplars - exemplar effects.
Discussion
The aim was to investigate whether there is any difference in learning speed, performance and knowledge representation depending on whether the learning is made by written verbalization or reading verbalized rules, and if the stimuli presentation analogue or propositional interact or form a single effect on learning. The intention was also to investigate whether any of these factors alone or together affect knowledge representation in the direction of being a rule-based or exemplar-based.
The present study supports Enqvist et al. (2006) results of higher performance caused by intervention when the Verbalized Individuals indicated more accurate judgments overall and that intervention performance effects is not only due to continuous cues, but could occur even for multiple-cue judgment tasks with binary cues if the intervention is transpired in a verbalized format. According to the learning speed no significant differences were shown even if the LI lack training feedback. An explanation could be that no feedback after every trial is necessary if the descriptions handed out by the Verbalized Individuals are structured and clear enough. The NVI showed lower performance in the training phase than the VI which strengthens the evidence that verbalization increase learning. These results could be explained by the verbal facilitation effects by Huff & Schwan (2008; 2012) who argue that visual recognition performance was higher with preverbalizations. When the VI in the present study were forced to write instructions for the LI increase their own visual recognition and also their judgment performance. Another reason could be that verbalization in writing both clarifies the criteria and how it correlates to the stimuli and in turn, works as an extra learning feedback, which forces the individual to specify relationships of cues or exemplars. Further, the results clearly demonstrate that it was a great learning advantage to present stimuli analogical than propositional, in contrast to previous studies. Stimuli in the format of analogues were in many aspects more beneficial irrespective of the form of verbalization or absence of feedback, which partly differs from Ainsworth (2006) that argues there is a balanced approach in which both text and pictures contributes to a more or less equal degree to knowledge acquisition. A negative trend in this regard is that the analogue stimuli seem to give a higher incorrectness at an early stage. Overall, the propositional conditions exhibiting the lowest outcome, while all three groups in the analogue condition were remarkably better. The analogical individuals have a higher error rate in the beginning of their judgments, which means that they had disadvantages in the beginning of the learning phase, but had the lowest percentage of errors in the end of the same phase, which may seem slightly contradictory. An explanation could be that analogues are harder to understand in the beginning, before the individual make a whole understanding but after understanding occurs, the performance increase very fast. It is quite clear that it is the VI, and the LI in the analogue condition that are the fastest learners (as illustrated by how fast the curve flattens out in Figure 1).
Olsson et al. (2006) describes the exemplar-based system as a flexible backup system that dominates when feedback or task does not allow induction of the cue abstraction system. A possible account could be that rich feedback as written instructions from the VI make it possible to rely on cue abstraction in a higher extent even if the judgment task is complex. However, cue abstraction processing could not be supported in present study with reverse significance for almost all groups which supports the assumption that pre-verbalizations influence subsequent visual processing and, consequently, knowledge acquisition argued by Yee & Sedivy (2006). Further, the degree of exemplar effects have not been affected by analogue or Propositional encoding (analogue - Proposition), similar to Juslin et al. (2003). Maybe, the current study can explain why the hypothesis of stimuli representation argued by Juslin et al. (2003) could not be supported. How the verbalization is formulated in the instructions seem to be important for what kind of knowledge representation that is used which also affect the learning and use of knowledge representation for the learning individuals as the written verbalization is their only feedback. When analyzing the verbalized instructions, 95% of the verbalized written instructions were formulated as “exemplar rules”, such as “if the bug has short legs, blue back and short nose the toxicity is 54”. The formulation of exemplar rules make the VI to rely on exemplar memory which is easier to verbalize even for the VI with propositional presentation. In turn, the LI are affected by the verbalized instructions to store whole exemplar instead of relying on cue abstraction regardless of stimuli presentation. These results also strengthen the conclusion that exemplar effects of the LI conditions could be explained by the theory of the exemplar-based system as a back-up system made by Olsson et al. (2006). The fact that both groups of LI (analogical and propositional) exhibiting exemplar effects specify that knowledge of the exemplars can be transferred. Previous research has shown proof for exemplar rules in categorization tasks (see for example Nosofsky, 1992), while present study indicate that some kind of exemplar rules also exist in multiple-cue judgment tasks as well. Maybe reading informative stimuli or descriptions of cue abstraction character create an analogue representation in the memory to easier make a comprehensive whole of the stimuli. The participants could therefore implicitly be forced to make exemplars of the propositions. These exemplars could be remarkable different from the exemplars in the analogue condition but fulfill the aim of an individual reference point. Even the NVI showed higher extent of exemplar effects for the propositional stimuli presentation, but not as high as the VI. Regardless of which knowledge representation that is conveyed in the VI condition, the fact remains that the LI even though they have no personal experience (outcome feedback) of the cue to be judge, show a similar learning curve as their VI indicating the use of verbalized facilitation effect (Huff & Schwan, 2008).
The analogue groups had the highest performance overall supported by Juslin et al. (2003), which indicates that the analogue presentation of stimuli will cause an increased dominance of exemplar-based processes, when this invites holistic encoding. As a logical consequence, a situation that gives benefits to exemplar processing provides the most accurate judgments when stimuli are presented analogously. Furthermore, the results of this study and previous research show that exemplar-based knowledge could be the regular result of cooperation, even without social interaction.
References
- Ainsworth S.E (2006) DeFT: a conceptual framework for learning with multiple representation. Learning and Instruction 16:183-198.
- Cooksey R. W (1996) Judgment analysis: Theory, methods and applications, CA: Academic Press. San Diego.
- DeLosh E. L, Busemeyer J. R, McDaniel M. A (1997) Extrapolation: The sine qua non for abstraction in function learning. Journal of Experimental Psychology: Learning, Memory, and Cognition 23:968–986.
- Enqvist T, Newell B, Juslin P, Olsson H (2006) On the role of causal intervention in multiple-cue judgment: Positive and negative effects on learning. Journal of Experimental Psychology: Learning, Memory, and Cognition 32:163-179.
- Erickson M.A, Kruschke J.K (1998) Rules and exemplars in category learning. Journal of Experimental Psychology 127:107-140.
- Estes, W. K (1994) Classification and cognition. Oxford: Clarendon Press.
- Hammond K. R, Stewart T. R (2001) The essential Brunswik: Beginnings, explications, applications. Oxford: Oxford University Press.
- Huff M, Schwan S (2008) Verbalizing events: overshadowing or facilitation?. Memory & Cognition 36:392-402.
- Huff M, Schwan S (2012) The verbal facilitation effect in learning to tie nautical knots. Learning and Instruction 22:376-385.
- Juslin P, Olsson H, Olsson A C (2003) Exemplar effects in categorization and multiple-cue judgment. Journal of Experimental Psychology: General 132:133-156.
- Medin D L, Schaffer M.M (1978) Context theory of classification learning. Psychological Review 85:207–238.
- Nosofsky R.M (1989) Further tests of an exemplar-simularity approach to relating identification and categorization. Perception & Psychophysics 45:279-290.
- Nosofsky R M (1992) Similarity scaling and cognitive process models. Annual Review of Psychology 43:25-53.
- Nosofsky R.M, Johansen M.K (2000) Exemplar-based accounts of “multiple system” phenomena in perceptual categorization. Psychonomic Bulletin & Review 7:375–402.
- Olsson A.C, Enkvist T, Juslin P (2006) Go with the flow! How to Master a Non-Linear Multiple Cue Judgment Task. Journal of Experimental Psychology: Learning, Memory and Cognition 32:1371-1384.
- Smith J.D, Minda J.P (2000) Thirty categorization results in search of a model. Journal of Experimental Psychology: Learning, Memory, and Cognition 26:3-27.
- Yee E, Sedivy J.C (2006) Eye movements to pictures reveal transient semantic activation during spoken word recognition. Journal of Experimental Psychology: Learning, Memory and Cognition 32:1-14.